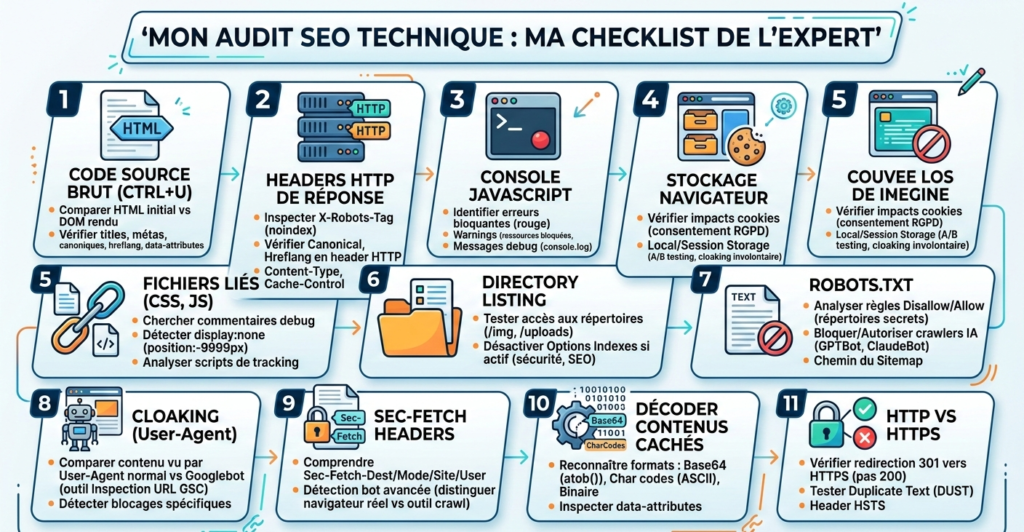
Inspecter une page comme un auditeur SEO : 11 réflexes à maîtriser
La plupart des référenceurs savent vérifier une balise title ou une meta description. C’est le b.a.-ba. Mais un véritable audit SEO technique va beaucoup plus loin : il faut savoir lire les headers HTTP, décoder du Base64, détecter du cloaking, et fouiller les recoins du code source que personne ne regarde.
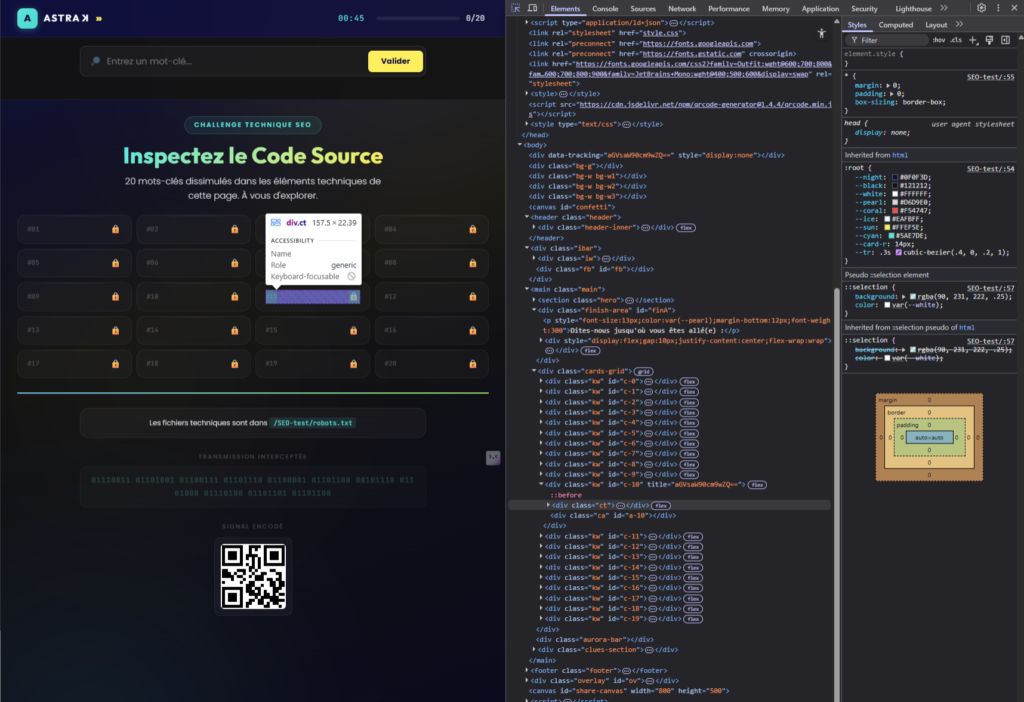
J’ai récemment travaillé sur un challenge SEO technique conçu par Astrak Agency. Le principe : une page web dans laquelle 20 mots-clés sont dissimulés dans des éléments techniques (meta tags, headers HTTP, JavaScript, fichiers CSS, données structurées, cloaking serveur…). Chaque mot-clé correspond à une compétence précise d’audit technique.
Ce type d’exercice rappelle une réalité que beaucoup de SEO oublient : tout ce qui est visible à l’écran ne représente qu’une fraction de la page. Le reste se trouve dans les headers, le JavaScript, les fichiers liés, et parfois dans ce que le serveur choisit de montrer selon qui visite.
Voici les 11 réflexes que j’en tire pour inspecter une page comme un auditeur SEO. Que vous soyez webmaster, SEO junior ou développeur qui se lance dans le référencement, ces vérifications devraient devenir automatiques.
À retenir en bref
- Ctrl+U ≠ F12 : le code source brut montre le HTML envoyé par le serveur, avant toute exécution JavaScript.
- Un x-robots-tag: noindex dans les headers HTTP bloque l’indexation même si la balise meta robots dit « index, follow ».
- Les headers Sec-Fetch permettent aux serveurs de distinguer un vrai navigateur d’un outil de crawl, même avec un User-Agent identique.
- Les crawlers IA (GPTBot, ClaudeBot, PerplexityBot) sont une 3e catégorie de visiteurs à tester en audit, en plus des humains et de Googlebot.
- Savoir décoder du Base64 avec atob() dans la Console suffit pour lire la majorité des contenus encodés.
1. Lire le code source brut (Ctrl+U)
C’est le réflexe le plus basique, et pourtant beaucoup de référenceurs ne le font pas correctement. Il y a une différence majeure entre le code source brut (Ctrl+U) et le DOM inspecté (F12 > Elements).
- Ctrl+U affiche le HTML tel que le serveur l’a envoyé, avant toute exécution JavaScript.
- F12 > Elements affiche le DOM après exécution du JavaScript : des éléments ont pu être ajoutés, modifiés ou supprimés.
Cette distinction est critique. Si votre contenu est généré par du JavaScript (React, Vue, Angular), Ctrl+U montrera une page quasi vide. C’est exactement ce que voit Googlebot au premier crawl, avant le rendering.
Dans le code source brut, voici ce qu’il faut vérifier systématiquement :
- La balise
<title>: contient-elle le mot-clé cible ? Est-elle unique ? - La
<meta name="description">: est-elle présente et pertinente ? - La
<link rel="canonical">: pointe-t-elle vers la bonne URL ? - Les
<link rel="alternate" hreflang="...">: les versions linguistiques sont-elles déclarées ? - Les balises Open Graph (
og:title,og:description,og:image) - Le bloc
<script type="application/ld+json">: les données structurées sont-elles valides ?
Les data-attributes : un angle mort courant
Les attributs data-* sont des attributs HTML personnalisés utilisés par le JavaScript pour stocker des données. En audit, on les survole souvent. Pourtant, ils peuvent contenir des informations significatives, y compris du contenu encodé en Base64.
<!-- Exemple : contenu caché en Base64 dans un data-attribute -->
<div data-tracking="aGVsaW90cm9wZQ==" style="display:none"></div>
<!-- Pour décoder, ouvrir la Console (F12) et taper : -->
atob('aGVsaW90cm9wZQ==')
// Résultat : "heliotrope"En SEO, les data-attributes sont partout : Google Tag Manager, scripts de tracking, A/B testing. Savoir les lire permet de comprendre ce que la page transmet aux outils tiers.
2. Inspecter les headers HTTP de la réponse
Le code source HTML n’est qu’une partie de la réponse du serveur. Les headers HTTP contiennent des directives invisibles dans le HTML et sont souvent négligés en audit SEO technique.
Comment voir les headers
- Ouvrir les DevTools (F12)
- Aller dans l’onglet Network (Réseau)
- Recharger la page
- Cliquer sur la première requête (le document HTML)
- Lire les Response Headers
Ce qu’on cherche dans les headers
| Header | Quoi vérifier |
|---|---|
x-robots-tag |
Directives pour les crawlers (noindex, nofollow, noai…). Équivalent HTTP de la balise meta robots, mais invisible dans le HTML. |
link |
Canonical et hreflang peuvent être déclarés ici (alternative au HTML). |
content-type |
Le type MIME et l’encodage. Un text/html; charset=utf-8 est attendu. |
cache-control |
Les directives de cache impactent le crawl budget et la fraîcheur indexée. |
strict-transport-security |
HSTS force le HTTPS. Bonne pratique de sécurité. |
Le piège classique : un x-robots-tag: noindex dans les headers bloque l’indexation même si la balise meta robots dans le HTML dit « index, follow ». Les headers HTTP sont prioritaires. C’est un piège fréquent après une migration : le serveur de staging envoyait un noindex en header, et personne ne l’a retiré en production.

3. Surveiller la Console JavaScript
La Console du navigateur (F12 > Console) affiche les messages générés par le JavaScript de la page. En audit technique, on y cherche trois choses :
- Des erreurs JavaScript (en rouge) : elles peuvent bloquer le rendering de contenu.
- Des warnings : ressources bloquées, mixed content, APIs dépréciées.
- Des messages de debug : les développeurs laissent parfois des
console.log()en production qui révèlent des informations internes.
Pourquoi c’est important pour le SEO ? Googlebot utilise un navigateur Chrome pour le rendering. Les erreurs JavaScript visibles dans la Console sont les mêmes erreurs que Googlebot rencontre. Une erreur qui empêche le chargement du contenu principal = contenu invisible pour Google.
Mon réflexe : après chaque chargement de page en audit, regarder la Console pendant 3 secondes. C’est le temps qu’il faut pour repérer un message rouge. Ça ne coûte rien et ça peut révéler un problème critique.
4. Explorer le stockage navigateur (cookies, localStorage)
Le navigateur stocke des données côté client via deux mécanismes principaux : les cookies et le localStorage. Pour y accéder : F12 > onglet Application (Chrome) ou Stockage (Firefox).
- Cookies : données envoyées au serveur à chaque requête. Impactent le consentement RGPD, les sessions, le tracking.
- Local Storage : données persistantes côté client uniquement. Utilisées pour les préférences, l’A/B testing, le tracking client-side.
- Session Storage : comme le localStorage mais effacé à la fermeture de l’onglet.
Pourquoi c’est important en SEO
Un bandeau RGPD mal implémenté peut bloquer le chargement du contenu principal si le consentement n’est pas donné. Problème : Googlebot ne donne pas son consentement. Le contenu reste invisible.
L’A/B testing pose un problème similaire. Si le JavaScript stocke une variante A/B dans le localStorage et modifie le contenu en conséquence, Googlebot peut voir une version différente de celle que voit l’utilisateur. C’est un cas de cloaking involontaire.
5. Suivre les fichiers liés (CSS, JS, fichiers annexes)
Une page HTML ne vit pas seule. Elle charge des fichiers CSS, JavaScript, des images, des polices. Chacun de ces fichiers peut contenir des informations utiles pour l’audit.
Les fichiers CSS
On pense rarement à lire le contenu brut d’un fichier CSS. Pourtant :
- Des commentaires de debug peuvent mentionner des environnements (staging, preprod), des noms de développeurs, ou des références internes.
- Des règles CSS avec
display: noneouposition: absolute; left: -9999pxcachent des éléments. Google les détecte et les dévalorise. - La taille et la structure du CSS impactent le LCP (Largest Contentful Paint).
Les fichiers JavaScript
Le JavaScript est le territoire le plus riche pour un auditeur technique :
- Des contenus générés dynamiquement (que Googlebot doit exécuter pour voir).
- Des redirections JavaScript (moins fiables que les 301 serveur pour le SEO).
- Des appels API qui chargent le contenu principal (risque de rendering tardif).
- Des scripts de tracking qui révèlent la stack technique du site.
6. Tester le directory listing
Le directory listing est une fonctionnalité de serveur Apache qui affiche la liste de tous les fichiers d’un répertoire quand il n’y a pas de fichier index.html. Pour le tester : naviguez vers un répertoire connu (ex: /img/, /uploads/, /css/) et voyez si le serveur affiche une liste de fichiers.
Trois problèmes si c’est actif :
- Sécurité : des fichiers sensibles (backups, configs, fichiers temporaires) peuvent être exposés.
- SEO : les pages de listing peuvent être indexées par Google (thin content, aucune valeur ajoutée).
- Découverte : le listing révèle des fichiers non référencés dans le HTML (images orphelines, pages de test, assets non utilisés).
En audit, testez au moins les répertoires /uploads/, /wp-content/uploads/, /img/, /images/, /assets/. Si le listing est actif, recommandez de le désactiver avec Options -Indexes dans le .htaccess.
7. Lire le robots.txt (vraiment)
Tout le monde sait qu’il faut vérifier le robots.txt. Peu de SEO le lisent vraiment ligne par ligne.
Au-delà des Disallow classiques, le robots.txt peut révéler :
- Des répertoires « secrets » : un
Disallow: /staging/ouDisallow: /beta/révèle l’existence d’environnements de test. - Des règles trop larges : un
Disallow: /tag/pensé pour bloquer les taxonomies WordPress peut accidentellement bloquer un article dont le slug contient « tag ». - Le blocage des crawlers IA : de plus en plus de sites bloquent GPTBot, ClaudeBot, PerplexityBot, ce qui les rend invisibles pour les réponses AI Overviews.
- Le chemin du sitemap : la directive
Sitemap:en bas du fichier est un point de départ pour l’audit de la structure.
# Exemple de robots.txt révélateur
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: *
Disallow: /admin/
Disallow: /staging/ # environnement de test exposé
Disallow: /nebula/ # répertoire suspect à investiguer
Allow: /
Sitemap: https://example.com/sitemap.xmlPoint d’attention en 2026 : Anthropic a segmenté ses crawlers en 3 bots distincts (ClaudeBot, Claude-User, Claude-SearchBot). On peut bloquer l’entraînement tout en autorisant la visibilité dans les réponses IA. C’est un arbitrage stratégique que de plus en plus de clients me demandent de trancher à Tours et ailleurs.
8. Tester le cloaking par User-Agent
Le cloaking consiste à servir un contenu différent selon le visiteur. C’est une violation des Google Search Essentials qui peut entraîner une action manuelle (pénalité).
Mais le cloaking peut aussi être involontaire. Des plugins de sécurité WordPress, des WAF (Cloudflare, Sucuri), ou des configurations serveur peuvent servir un contenu dégradé aux bots sans que le propriétaire du site le sache.
Comment tester
Méthode 1 : extension navigateur. Installez « User-Agent Switcher and Manager » (Chrome/Firefox), changez l’UA en Googlebot, et rechargez la page.
Méthode 2 : ligne de commande.
# Voir la page comme Googlebot
curl -A "Googlebot/2.1 (+http://www.google.com/bot.html)" https://example.com/
# Voir la page comme GPTBot (crawler OpenAI)
curl -A "Mozilla/5.0 AppleWebKit/537.36 +https://openai.com/gptbot" https://example.com/Méthode 3 : Google Search Console. L’outil « Inspection d’URL » montre exactement ce que Googlebot voit. C’est la référence.
Quoi comparer
| Élément | Navigateur | Googlebot | Diagnostic |
|---|---|---|---|
| Title | « Mon titre SEO » | « Mon titre SEO » | OK |
| Title | « Mon titre SEO » | « Access denied » | Cloaking |
| Contenu principal | Article complet | Page vide | Rendering JS bloqué |
| Code HTTP | 200 | 403 | Blocage bot |
Certains serveurs bloquent spécifiquement les crawlers IA (GPTBot, ClaudeBot, PerplexityBot) avec des messages « Accès refusé » tout en servant le contenu normal à Googlebot. Ce n’est pas du cloaking au sens Google (pas de pénalité), mais ça rend le site invisible pour les réponses IA. Un problème croissant que j’observe chez mes clients en Indre-et-Loire comme au niveau national.

9. Comprendre les headers Sec-Fetch (détection de bot avancée)
C’est probablement la leçon la plus surprenante, et la moins connue en SEO.
Les navigateurs modernes envoient automatiquement des headers Sec-Fetch-* à chaque requête. Ces headers indiquent au serveur comment la requête a été déclenchée :
| Header | Valeur navigateur | Signification |
|---|---|---|
Sec-Fetch-Dest |
document |
La requête vise un document HTML |
Sec-Fetch-Mode |
navigate |
L’utilisateur navigue vers la page |
Sec-Fetch-Site |
none |
La requête vient de la barre d’adresse (pas d’un lien) |
Sec-Fetch-User |
?1 |
La requête est déclenchée par un humain |
Les outils de crawl SEO (Screaming Frog, Sitebulb) et les commandes curl n’envoient PAS ces headers. Un serveur qui les vérifie peut donc distinguer un vrai navigateur d’un outil de crawl, même si le User-Agent est identique.
Concrètement : vous pouvez envoyer un curl avec un User-Agent Chrome parfait, le serveur le détectera quand même comme un bot si les headers Sec-Fetch sont absents.
# curl avec UA Chrome MAIS sans Sec-Fetch = détecté comme bot
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/131.0.0.0" https://example.com/
# curl avec UA Chrome ET Sec-Fetch = vu comme un vrai navigateur
curl https://example.com/ \
-H "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/131.0.0.0" \
-H "Sec-Fetch-Dest: document" \
-H "Sec-Fetch-Mode: navigate" \
-H "Sec-Fetch-Site: none" \
-H "Sec-Fetch-User: ?1"Si vous soupçonnez un cloaking mais que le test avec un User-Agent modifié ne révèle rien, essayez avec les headers Sec-Fetch. C’est aussi la raison pour laquelle certains sites semblent fonctionner dans le navigateur mais pas dans Screaming Frog.
10. Savoir décoder (Base64, binaire, char codes)
Un auditeur SEO technique doit savoir reconnaître et décoder les encodages courants. Pas besoin d’être développeur : la Console du navigateur suffit.
Base64
Reconnaissable aux caractères A-Z, a-z, 0-9, +, / et souvent un = ou == à la fin.
// Dans la Console (F12) :
atob('aGVsaW90cm9wZQ==')
// Résultat : "heliotrope"Où le trouver en audit : data-attributes, payloads de tracking, cookies, URL encodées.
Char codes (codes ASCII)
Un tableau de nombres qui représentent des lettres : [109, 111, 114, 115, 101].
// Dans la Console :
[109, 111, 114, 115, 101].map(c => String.fromCharCode(c)).join('')
// Résultat : "morse"Où le trouver en audit : scripts JavaScript obfusqués, configurations de tracking, paramètres URL.
Binaire
Des suites de 0 et 1 groupées par 8 : 01101000 01101001.
// Dans la Console :
'01101000 01101001'.split(' ').map(b => String.fromCharCode(parseInt(b, 2))).join('')
// Résultat : "hi"Plus rare en pratique, mais ça peut apparaître dans des configurations serveur ou du contenu obfusqué.
11. Vérifier HTTP vs HTTPS
En 2026, HTTPS est la norme. Mais il est toujours utile de tester ce qui se passe quand on accède à une page en HTTP (sans le « s ») :
- Redirection 301 vers HTTPS : c’est le comportement attendu. Vérifiez qu’elle est bien en 301 (pas 302).
- Réponse 200 en HTTP : la page répond sans rediriger = DUST (Duplicate URL Same Text). Le contenu existe en double.
- Contenu différent : le serveur peut servir un contenu différent en HTTP vs HTTPS. Cas rare mais réel.
- HSTS : le header
Strict-Transport-Securityforce le navigateur à utiliser HTTPS même si l’utilisateur tape HTTP.
Test rapide : curl -I http://example.com/. Si la réponse est un 301 vers https://, c’est correct. Si c’est un 200, il y a un problème de duplicate.
Ce que ça change pour l’audit SEO en 2026
Ce challenge met en lumière trois évolutions importantes pour le métier.
La détection de bot est plus sophistiquée
Les serveurs ne se contentent plus de vérifier le User-Agent. Les headers Sec-Fetch, la détection de navigateur headless (navigator.webdriver), et les signatures de requêtes permettent de distinguer un humain d’un outil avec une précision croissante. Pour un auditeur, cela signifie que les résultats de Screaming Frog ou Sitebulb ne représentent pas toujours ce que Googlebot ou un utilisateur voit réellement.
Les crawlers IA sont un nouveau paramètre
Avec GPTBot, ClaudeBot, PerplexityBot et leurs variantes, il y a désormais une troisième catégorie de visiteurs à prendre en compte. Un site peut être parfaitement indexé par Google mais totalement invisible pour les réponses de ChatGPT ou Perplexity. L’audit technique doit désormais inclure un test d’accessibilité IA. J’ai détaillé ce sujet dans mon guide complet sur les AI Overviews.
L’inspection manuelle reste irremplaçable
Les outils automatisés (Screaming Frog, Sitebulb, Semrush) sont indispensables pour l’analyse à grande échelle. Mais pour comprendre ce qui se passe réellement sur une page spécifique, rien ne remplace l’inspection manuelle : Ctrl+U, F12, curl. C’est la différence entre un audit SEO superficiel et un audit qui trouve les vrais problèmes.
Un bon auditeur SEO ne se contente pas de lire ce qui est visible. Il lit ce que le serveur envoie, ce que le JavaScript génère, ce que les headers déclarent, et ce que les fichiers liés contiennent. La page que l’utilisateur voit n’est que la partie émergée de l’iceberg.
Questions fréquentes
Quelle est la différence entre Ctrl+U et F12 pour un audit SEO ?
Ctrl+U affiche le code source brut envoyé par le serveur, avant toute exécution JavaScript. F12 > Elements affiche le DOM après exécution du JS : des éléments ont pu être ajoutés ou modifiés. Pour un audit SEO, Ctrl+U montre ce que Googlebot voit au premier crawl, tandis que F12 montre le résultat après rendering.
Comment détecter du cloaking sur un site web ?
Trois méthodes : (1) utiliser une extension User-Agent Switcher pour visiter la page en tant que Googlebot, (2) utiliser curl en ligne de commande avec le User-Agent Googlebot, (3) utiliser l’outil Inspection d’URL de Google Search Console qui montre exactement ce que Google voit. Comparez le titre, le contenu et le code HTTP entre navigateur et bot.
Pourquoi un site fonctionne dans le navigateur mais pas dans Screaming Frog ?
Le serveur vérifie probablement les headers Sec-Fetch. Les navigateurs envoient automatiquement ces headers (Sec-Fetch-Dest, Sec-Fetch-Mode, etc.) mais les outils de crawl comme Screaming Frog ne les envoient pas. Le serveur détecte donc le crawl comme un bot et peut bloquer l’accès ou servir un contenu différent.
Comment décoder du Base64 trouvé dans le code source ?
Ouvrez la Console du navigateur (F12 > Console) et tapez atob(‘votre_chaine_base64’). Le résultat décodé s’affiche immédiatement. Le Base64 se reconnaît aux caractères A-Z, a-z, 0-9, +, / et souvent un = ou == à la fin.
Besoin d’un audit SEO technique de votre site ?
Ces 11 réflexes sont ceux que j’applique systématiquement quand j’audite un site pour mes clients à Tours et en Indre-et-Loire. Un audit technique complet va encore plus loin : analyse de crawl à grande échelle, vérification des Core Web Vitals, audit du maillage interne, analyse des logs serveur.
Si vous voulez savoir ce que Google voit réellement sur votre site (et ce qu’il ne voit pas), contactez-moi pour un diagnostic gratuit. Je vous montre les problèmes concrets et les actions prioritaires pour les corriger.
Ping : Référencement naturel à Tours : le guide complet pour les PME (2026)